INDICADORES TURÍSTICOS (2020)

APUNTES PERSONALES
Los conjuntos son grupos formados por una serie de elementos que poseen ciertas propiedades. Ejemplo: El conjunto Argentina esta formado por 23 provincias (elementos), Buenos Aires es un elemento que pertenece a ese conjunto. El elemento Montevideo no pertenece a ese conjunto ya que no es una provincia de Argentina.
Hay dos formas de expresar conjuntos:
POR EXTENSIÓN O NUMERACIÓN ➜ enumera los elementos que forman parte del conjunto (Ej: A = {a, i , u, e, o} ).
POR COMPRENSIÓN O PROPIEDAD ➜ da un criterio que permite decidir con certeza si un elemento pertenece a un conjunto o no (Ej: A = { x / x es una vocal } ).
∉ → no pertenece a...

TABLA DE CONTINGENCIA

Es una forma de representar el diagrama de Venn cuando hay demasiados conjuntos y elementos. En esta tabla se ven 6 conjuntos: menores y 21 años, entre 21 y 35 años, mayores de 35 años, muy precavidos, precavidos y peligrosos. Cada conjunto tiene su propio numero de elementos.
MARGINALES ➜ son los valores que están al margen, representan el total de elementos en un conjunto (ej: el conjunto "muy precavidos" tiene un total de 70 elementos, el conjunto "menores de 21 años" tiene 90 elementos, etc).
INTERSECCIÓN ➜ son los elementos comunes entre dos o mas conjuntos (ej: el valor 15 es la intersección entre los conjuntos "muy precavidos" y "menores de 21 años").
CONDICIONAL ➜ comparación que relaciona una intersección y su marginal (ej: se puede condicionar el valor 15 con el total de menos de 21 años que es 90).
CUADRAR ➜ situación que se da cuando la suma de los marginales inferiores da el mismo resultado que la suma de los marginales del costado (en este caso es 190). Si una tabla no cuadra, no esta bien hecha.
-----
RAZÓN Y PROPORCIÓN
RAZÓN ➜ cociente o comparación entre dos unidades o cantidades.
Si decimos que en un hotel se gastan $12000 en electricidad cada 10 habitaciones.
La razón seria la siguiente:

{kind=link}
*se lee "12000 es a 10".
*el numero de arriba llamado "antecedente" y el de abajo "consecuente", pueden invertirse.
El resultado de esta razón da $1200 por cada habitación, este tipo de información sirve para comparar los gastos con otros hoteles.
PROPORCIÓN ➜ igualdad entre dos razones.
Dada esa razón podríamos decir que entonces se gastan $24000 cada 20 habitaciones.
Esa es la proporción:

*se lee "1200 es a 10, como 24000 es a 20".
Para confirmar que es una proporción, el producto (multiplicación) entre los extremos (en este caso 12000 y 20) tiene que dar lo mismo que el producto entre los medios (10 y 24000)
12000 * 20 = 240000
10 * 24000 = 240000
PORCENTAJE
Para calcular un porcentaje de un total, hay que multiplicar el total por el porcentaje deseado y dividir el resultado por cien.
45% de 120 = 120 * 45 / 100 = 54
-
Para calcular el total, hay que multiplicar el valor del porcentaje por 100 y dividirlo por el porcentaje.
Si el 45% es 54 = 54 * 100 / 45 = 120
-
Para calcular que porcentaje del total es un numero, hay que multiplicar el numero por 100 y dividirlo por el total.
Si el total es 120 entonces 54 es el... = 54 * 100 / 120 = 45%
-
Para expresar un porcentaje en coeficiente simplemente hay que dividirlo por 100.
45% = 45/100 = 0,45
PARÁMETRO ➜ todo análisis que se relacione sobre la población.
ESTADÍSTICA ➜ todo análisis que se relacione con la muestra.
2) DISEÑO DEL EXPERIMENTO ➜ seleccionar la técnica de recolección de datos (observación directa, entrevista, encuesta, investigación documental) que permita obtener información eficientemente (mínimo costo y tiempo posible). También se define el tamaño de la muestra, su calidad requerida y tipo de datos necesarios para resolver el problema.
3) RECOLECCIÓN DE DATOS ➜ etapa de mayor importancia en la cual se realiza una recolección optima siguiendo reglas estrictas para obtener la información deseada, si se siguen estas reglas los datos van a ser de calidad.
4) PROCESO DE DATOS Y SU DESCRIPCIÓN ➜ se elaboran cuadros estadísticos de trabajo y de referencia, graficas y cálculos de medidas estadísticas según el proceso descriptivo o inferencial seleccionado, de esta forma se exponen los datos muestrales usando representaciones tabulares, graficas y medidas estadísticas para describir los resultados.
5) INFERENCIA ESTADÍSTICA Y CONCLUSIONES ➜ etapa de contribución importante en la que se define el nivel de confianza y significación del proceso inferencial, orientando a quienes deben tomar una decisión sobre el tema objeto de estudio y estableciendo una conclusión acerca del problema junto con sugerencias para la solución del mismo.
-----
En estadística los datos se pueden analizar de forma univariable, bivariable o multivariable.
UNIVARIABLE ➜ se estudia una sola variable en relación a un dato (Ej: tipo de turismo realizado por el turista).
BIVARIABLE ➜ se estudian dos variables en relación a un dato (Ej: relación entre el gasto y el tipo de turismo).
MULTIVARIABLE ➜ se estudian mas de dos variables en relación a un dato.
CONTINUAS ➜ pueden tomar cualquier valor numérico real, ya sea entero o fraccionario en un intervalo previamente especificado.
DATOS
Son la información sobre la variable de la muestra o población.
DATO ATÍPICO O OUTLIER ➜ dato que no se relaciona con los demás (Ej: entre un conjunto datos donde todos son de alrededor de 30 años aparece una de 150 años). Hay que analizarlo para saber si fue mal incorporado o si de verdad es así y porque ocurrió. Normalmente se termina excluyendo.
CORTE TRANSVERSAL ➜ los datos se obtienen a través de una muestra, observando las unidades de análisis en un único periodo de tiempo y evitando el sesgo por selección.
DATOS DE SERIES DE TIEMPO ➜ se analiza una unidad en varios periodos de tiempo tomando en cuenta el orden cronológico.
DATOS DE PANEL ➜ combina el corte transversal con los datos de series de tiempo. Analiza varias unidades en varios periodos de tiempo creando una base de datos mixta.
LA MUESTRA
Estudiar al total de la población (que representa al universo o conjunto universal) es muy costoso, requiere un planteo y realización muy complejo, y el hecho de que la población pueda estar cambiando constantemente hace de ese análisis casi imposible. Es por eso que este estudio se realiza cada 10 años a través de un "censo".
Por lo tanto vamos a analizar solo una parte (un subconjunto) de ese universo, parte que se va a llamar "muestra". Analizar utilizando muestras se denomina "muestreo", y sirve para saber como funciona una parte para determinar como funciona el todo.
CARACTERÍSTICAS DE LA MUESTRA
La muestra siempre debe ser representativa, por lo que tiene que evitar 3 cosas:
1) CONVENIENCIA MUESTRAL ➜ se elige de alguna manera a quienes incluir en la muestra y a quienes no.
2) NO RESPUESTA ➜ solo una parte contesta la encuesta, perdiendo la representatividad.
3) RESPUESTA VOLUNTARIA ➜ unidades que responden voluntariamente con una inclinación tomada (si se hace una encuesta y se les pide a las personas que participen voluntariamente deja de ser una muestra representativa).
Si no se evitan estos puntos se pueden producir dos tipos de sesgo:
SESGO POR OMISIÓN ➜ no se cumple con el punto "1", es decir, se omiten de la muestra a aquellos que no me convengan para obtener la respuesta que quiero.
SESGO POR INCLUSIÓN ➜ no se cumple con los puntos "1" y "3", es decir, hago una encuesta voluntaria pero solamente incluyo en la muestra a aquellos que me hayan dado la respuesta que me convenga.
MEDIDAS
Ejemplo de media:
M = { 2, 10, 4, 8, 3, 6 }
Esta muestra tiene seis elementos, por lo que para sacar el promedio hay que dividir la suma de los elementos por esa cantidad.
x̄ = ( 2 + 10 + 4 + 8 + 3 + 6 ) / 6 = 5,5
Otra forma de calcular el promedio es con la sumatoria de cada dato multiplicado por su frecuencia.
➢ MEDIANA
Busca el dato que divide a la muestra en partes iguales, siendo tanto una medida de unidad central como también de posición. No esta condicionada por outliers. Se representa como "Me".
Ejemplo de mediana cuando la cantidad de datos es impar:
Si los datos son { 3, 6, 2, 8, 9, 10, 4 } primero hay que ordenarlos de menor a mayor. Después hay que buscar la posición donde haya la misma cantidad de datos a la izquierda que hacia la derecha, ese dato es la mediana.
2, 3, 4, 6, 8, 9, 10 = 6 es la mediana
Otra forma de saber cual es la posición de la mediana es haciendo un calculo (donde n = cantidad de datos o tamaño de la muestra).
( n + 1 ) / 2 = ( 7 + 1 ) / 2 = 4
Ahora sabemos que la mediana es el dato que esta en la posición 4.
Ejemplo de mediana cuando la cantidad de datos es par:
Si los datos son { 1, 3, 3, 6, 7, 7, 9, 10 } primero hay que encontrar los dos datos que separan la muestra en partes iguales y promediarlos, el resultado da la mediana.
1, 3, 3, 6, 7, 7, 9, 10 = ( 6 + 7 ) / 2 = 6,5 es la mediana
Otra forma se saber cual es la posición de los datos que hacen la media es con cálculos (donde n = cantidad de datos o tamaño de la muestra).
n / 2 = 8 / 2 = 4
( n / 2 ) + 1 = ( 8 / 2 ) + 1 = 5
Ahora sabemos que la mediana es el promedio entre los datos que están en la posición 4 y 5.
➢ MODA
FRECUENCIA ABSOLUTA
➜ cantidad de veces que aparece un dato u observación en la muestra. La
suma de la frecuencia de todos los datos tiene que ser igual a la
cantidad de datos en la muestra.
La Moda explica como están concentrados los datos con respecto a uno o varios en especial, en otras palabras es el dato que tiene la mayor frecuencia. Se representa como "Mo". Puede ser unimodal (un solo dato que aparece con mayor frecuencia), bimodal (dos datos tienen la misma mayor frecuencia) o multimodal (varios datos con la misma mayor frecuencia).
Ejemplo unimodal: { 2, 3, 6, 6, 7, 8, 10 } = la moda de la nuestra es 6.
Ejemplo bimodal: { 2 , 3, 3, 4, 6, 6, 8 } = la moda de la muestra es 3 y 6.
FRECUENCIA RELATIVA ➜ como esta un dato en proporción a la cantidad total de datos (que porcentaje forma del total de datos).
1 + 3,322 * LOG10(n)
*LOG10 = logaritmo decimal
VALOR MÍNIMO ➜ dato con el valor mas bajo.
VALOR MÁXIMO ➜ dato con el valor mas grande.
RANGO ➜ diferencia (resta) entre el valor máximo y mínimo.
ANCHO ➜ rango dividido cantidad de intervalos.
INTERVALO ➜ se separa en intervalo cerrado (o limite inferior) y abierto (o limite superior, que es un valor de referencia pero no pertenece al intervalo). Para calcularlo se toma el valor mínimo y se le suma el ancho, al resultado se le vuelve a sumar el ancho, y así constantemente hasta llegar al valor máximo.
FRECUENCIA ➜ cantidad de datos que hay entre el intervalo cerrado y abierto (sin contar el abierto).
MARCA DE CLASE ➜ promedio entre el valor del dato y su intervalo.
-----
MEDIDAS DE POSICIÓN
➢ CUANTILES
Partes iguales en las que se puede dividir la muestra, se pueden clasificar en:
MEDIANA ➜ dos partes iguales (50%).
CUARTIL ➜ cuatro partes iguales (25%).
QUINTIL ➜ cinco partes iguales, usualmente no se usa (20%).
DECIL ➜ diez partes iguales, se usa mucho en distribución de la ingresos (10%).
PERCENTIL ➜ cien partes iguales (1%).
El calculo es la cantidad de datos dividido por el cuantil, multiplicado por la posición que se desea obtener.
Ejemplo para hallar el percentil de 75 (si n = cantidad de datos o tamaño de la muestra):
( n / 100 ) * 75
RANGO INTERCUARTÍLICO (RIC) ➜ analiza a través de la mediana como están distribuidos los datos del 50% alrededor de ella. Para calcularlo se resta el valor del Q3 (cuartil 3) menos el valor del Q1. También es una medida de dispersión o variabilidad.


Ejemplo si la población es { 5, 6, 6, 7, 8 }.



ESTADÍSTICA DESCRIPTIVA
GRÁFICOS ➜ Permiten representar los datos de una forma accesible para todos, siendo los gráficos de barras los mas utilizados para el análisis de variables cualitativas o categóricas.
➢ TIPOS DE GRÁFICOS
GRÁFICO DE BARRAS ➜ Están formados por un eje de valores y un eje de escala de los valores estadísticos, pudiendo ser verticales u horizontales. El ancho de todas las barras debe que ser uniforme, y su altura proporcional. Este tipo de gráfico sirven para el análisis de una variable, y como se suele usar para variables cualitativas no necesitan un orden especifico, a diferencia de si habláramos de variables cuantitativas.
GRÁFICO DE BARRAS SUPERPUESTAS ➜ Pueden ser adyacentes o superpuestas, su objetivo es comparar la magnitud de dos o mas variables.

HISTOGRAMA ➜ Gráfico de barras para variables numéricas que indica los patrones de un conjunto de datos en un numero de clases o intervalos pequeños y no solapados (adyacentes). En otras palabras, sirve para ver de forma fácil y rápida la distribución de los datos en los intervalos. Hay que tener muy en cuenta el ancho del intervalo o clase para evitar interpretaciones erróneas, y su condición principal es que los datos deben estar ordenados.
Un histograma puede distribuirse de diferentes formas:
DISTRIBUCIÓN SIMÉTRICA ➜ También llamada distribución en campana. Los datos ubicados en el medio tienen la misma frecuencia, por lo que la media, moda y mediana son aproximadamente iguales.
DISTRIBUCIÓN SESGADA A LA DERECHA ➜ La moda es menor que la mediana, y la mediana menor que la media.
DISTRIBUCIÓN SESGADA A LA IZQUIERDA ➜ La moda es mayor a la mediana, y la mediana mayor que la media.
DISTRIBUCIÓN UNIFORME ➜ Todos los valores son aproximadamente iguales.

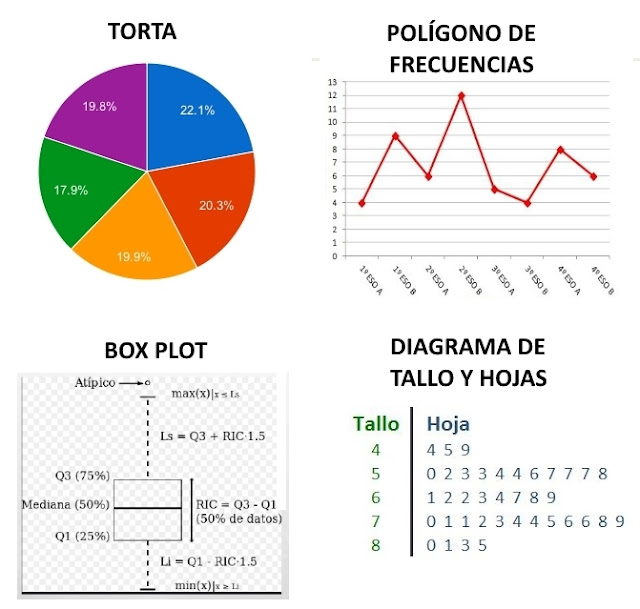
GRÁFICO DE TORTA ➜ También llamado de pastel, circular o por sectores. Desagrega en porcentaje las observaciones sobre una superficie circular, permitiendo comparar fácilmente las proporciones de cada clase en el total.
POLÍGONO DE FRECUENCIAS ➜ Permite ver la distribución de frecuencias en cada intervalo o clase uniendo ambos entre si. Se puede analizar con frecuencias absolutas, relativas o acumuladas. Este tipo de gráfico puede superponerse con un histograma.
BOX PLOT ➜ También llamado diagrama de caja y bigotes. Permite ver medidas robustas para analizar como esta distribuida la muestra alrededor de la mediana, identificar valores atípicos, cercanos y lejanos, y la dispersión de datos en cada rango. Mientras mas dispersos estén los datos mas alejada va a estar la mediana ese cuadrante y mas área va a tener (si la mediana esta mas hacia la izquierda o Q3 significa que los datos del lado derecho o Q1 están mas dispersados).
DIAGRAMA DE TALLO Y HOJAS ➜ Similar al histograma, pero sus datos se exhiben de una forma esquematizada como barras horizontales. El tallo representa los primeros valores y las hojas las unidades
COMBINATORIA
Es la rama de la matemática que analiza los elementos y determina sus posibilidades de agrupación.
FACTORIAL ➜ Multiplicar un numero desde su valor hacia abajo, se representa con un símbolo de exclamación (!). Nos dice cuantas posibilidades de orden hay para una cantidad de datos.
Ejemplo: La palabra "ejemplo" tiene 7 letras.
El factorial de 7! = 7 * 6 * 5 * 4 *3 * 2 * 1 = 5040
Eso significa que con esas 7 letras podemos armar 5040 palabras.
*El factorial de 0! siempre es igual a 1.
Depende de la forma en que se agrupen los elementos se puede hablar de:
COMBINACIONES ➜ No importa el orden
PERMUTACIONES ➜ Importa el orden, se trabaja con todos los elementos. Si hay al menos un elemento que se repite es una permutación con repetición, si todos los elementos son diferentes es una permutación sin repetición.
VARIACIONES ➜ Importa el orden, no se trabaja con todos los elementos. Puede ser con repetición o sin repetición.

Ejemplo combinación: Si llamo al frente de la clase a 3 estudiantes: Alicia, Beatriz y Carolina. No importa a quien llame primero, puedo llamar primero a Carolina, Alicia y a Beatriz y va a ser lo mismo, por lo que no importa el orden de los elementos.
Ejemplo permutación: Si en una carrera hay 8 participantes. El orden de llegada a la meta de cada participante si importa porque quieren obtener el primer lugar, y si es una carrera de 8 participantes todos van a participar por lo que se trabaja con todos los elementos.
Ejemplo variación: Si en un curso de 8 estudiantes se va a votar un presidente y un vicepresidente. El orden si importa ya que presidente no es lo mismo que vicepresidente y ambos van a realizar diferentes funciones, y de 8 estudiantes solamente voy a elegir a 2 por lo que no se trabaja con todos los elementos.
Ejemplo repetición: Si tengo la palabra "cama". El orden de las letras si importa ya que no es lo mismo "cama" que "amac", estoy usando todas las cuatro letras de la palabra por lo que se trabaja con todos los elementos, y hay repetición ya que al menos uno de los elementos se repite (en este caso la letra 'a' que aparece dos veces). Es una permutación con repetición.
*Si el enunciado de un problema menciona la palabra "distintos" significa que los elementos no pueden repetirse.
TRIANGULO DE PASCAL O TARTAGLIA

Funciona para obtener los coeficientes del desarrollo de la potencia de un binomio (también llamado Binomio de Newton). Para armarlo se va sumando un dígito con el que tiene al lado, y el resultado se pone abajo entre medio de ambos:
1 + 1
1 + 2 + 1
1 + 3 + 3 + 1
1 + 4 + 6 + 4 + 1
Y se puede seguir infinitamente. Usando este triangulo se pueden resolver binomios de la siguiente forma:
Si el binomio es ( a + b )4 el triangulo se interpreta de la siguiente forma
1 + 1 = ( a + b)^1
1 + 2 + 1 = ( a + b )^2
1 + 3 + 3 + 1 = ( a + b )^3
1 + 4 + 6 + 4 + 1 = ( a + b )^4
La fila con el exponente que corresponde al binomio que queremos buscar tiene 5 dígitos, es decir que nuestro resultado va a tener 5 términos.
( a + b )4 = __ + __ + __ + __ + __
Los números de la fila que corresponde a nuestro binomio nos indican el coeficiente de cada termino.
( a + b )4 = 1 + 4 + 6 + 4 + 1
El primer termino del binomio es la letra 'a', a esta letra se le va a agregar el exponente del binomio y va a ir disminuyendo hacia la derecha de termino en termino.
( a + b )4 = 1a4 + 4a^3 + 6a^2 + 4a^1 + 1
El segundo termino es la letra 'b', se va a hacer algo similar excepto que como esta a la derecha el exponente mas alto también va a estar a la derecha, y va a ir disminuyendo hacia la izquierda.
( a + b )4 = 1a4 + 4a^3b^1 + 6a^2b^2 + 4a^1b^3 + 1b4
Si en lugar de "a + b" fuera "a - b" los símbolos irían intercalados.
( a - b )4 = 1a4 - 4a^3b^1 + 6a^2b^2 - 4a^1b^3 + 1b4
ENCONTRAR UN TERMINO
Puede que se nos pida encontrar un termino (por ejemplo el quinto termino) de un binomio sin hacer el desarrollo entero
Para hallarlo hay que tener en cuenta que a cada termino del binomio se le asignan dos números:
( a + b )4 = 1a4 + 4a^3b^1 + 6a^2b^2 + 4a^1b^3 + 1b4
En este caso seria ( 4 0 ), (4 1), (4 2), (4 3) y (4 4).
¿Que significan estos números? El primero es el exponente del binomio, en este caso el binomio esta elevado al 4. El segundo numero es el termino menos 1.
Por ejemplo si queremos encontrar (4 2) significa que queremos buscar el tercer termino de un binomio elevado al 4. O si decimos ( 7 5 ) significa el sexto termino de un binomio elevado al 7.
Si queremos encontrar el sexto termino de ( x + 5 )^9 estamos hablando de (9 5).
Para encontrar el exponente de "x" hay que restar ambos números, en este caso 9-5=4. Así que sabemos que "x" va a estar elevado al 4.
El exponente de "5" es igual al segundo numero, en este caso 5.
Entonces el sexto termino es ( x^4 + 5^5)^9
PROBABILIDADES
PROBABILIDAD ➜ Indica la posibilidad de que un evento ocurra realmente cuando se sabe todas las posibilidades teóricas de su ocurrencia.
Una de las formas de determinar la probabilidad es determinar los casos u ocurrencias posibles en función de los casos totales (es una razón).
EXPERIMENTO ➜ Todo proceso que genera una observación.
EXPERIMENTO ALEATORIO ➜ Se todas las posibilidades que hay (ej: un dado) pero no tengo certeza sobre lo que va a salir. En otras palabras son aquellos en los que no se puede determinar el resultado de antemano, y estos resultados son diferentes bajo las mismas condiciones.
SUCESO O EVENTO ALEATORIO ➜ Cada uno de los resultados posibles de un experimento aleatorio. Es impredecible, incierto y no tiene ningún patrón.
ESPACIO MUESTRAL ➜ Relacionado al conjunto universal. Es el subconjunto de la muestra que contiene todos los resultados posibles del experimento.
Ejemplo: Si tiro un dado el espacio muestral (representado como una S) va a ser el siguiente.
S = {1, 2, 3, 4, 5, 6}
A partir de esos resultados se pueden pensar dos eventos diferentes, un evento A y un evento B.
A: {arrojar un dado y que salga par}; A = {2, 4, 6}
B: {arrojar un dado y que salga impar}; B = {1, 3, 5}
Para calcularlo en porcentaje hay que dividir la cantidad de posibles resultados por el total de posibilidades. Por ejemplo si quiero saber el porcentaje de la probabilidad de que un dado salga par, se que hay 3 posibilidades de un total de 6.
P(A) = 3 / 6 = 0,5 * 100 = 50%
Hay un 50% de que en el dado salga un numero par.
➢ REGLAS DE LA PROBABILIDAD
Al analizar probabilidades nos basamos en algunos postulados:
POSTULADOS ➜ También llamados principios, reglas o axiomas. Establecen verdades indiscutibles y a través de ellos se construye la teoría de probabilidad. Estos postulados son la no negatividad, normalización y aditividad.
NO NEGATIVIDAD ➜ La probabilidad de un evento siempre es igual o mayor a 0 (por ejemplo no se puede tener una probabilidad del -10%).
*no confundir probabilidad con variación porcentual, que si puede dar negativo (ej: los viajes en el 2020 bajaron un -80% en relación con el año anterior).
NORMALIZACIÓN ➜ La probabilidad del espacio muestral es 1 (o 100%). El resultado siempre va a estar entre 0 y 1.
ADITIVIDAD ➜ Los conjuntos son disjuntos o mutuamente excluyentes (aquellos que no tienen intersección, es decir que no tienen nada en común o que es un conjunto vació). Esto significa que la probabilidad de que ocurra la unión va a ser igual a la probabilidad de que ocurra el evento A mas la probabilidad de que ocurra el evento B. P ( A U B ) = P(A) + P(B).
CONJUNTOS MUTUAMENTE EXCLUYENTES ➜ Aquellos cuya intersección es nula (conjunto vacío).
CONJUNTOS COLECTIVAMENTE EXHAUSTIVOS ➜ Aquellos cuya unión da como resultado el espacio muestral o total de elementos.
Cuando los conjuntos no son disjuntos, es decir que la intersección no es nula, se le va a restar probabilidad de esa intersección para no contarla doble:
P ( A U B ) = P(A) + P(B) - P(A∩B)
FORMULA DE PROBABILIDAD ➜ También llamada ley de Laplace. Es la razón entre numero total de casos favorables y el total de casos posibles, y siempre va a dar como resultado un valor entre 0 y 1.

➢ ENFOQUES DE ANÁLISIS DE PROBABILIDAD
ENFOQUE FRECUENTISTA ➜ Relacionada con la ley de los grandes números. Analiza las probabilidades por la relación de las soluciones favorables sobre el total de casos posibles. Esto significa que mientras mas veces se repita el experimento mejor posibilidad hay de obtener la frecuencia con la que ocurre cada resultado. Es un calculo de probabilidad a priori y posteriori.
ENFOQUE BAYESIANO ➜ Enfoque moderno subjetivo relacionado con las experiencias previas que condiciona situaciones en base a probabilidades ya establecidas. Analiza probabilidad de ocurrencia de hechos que se actualiza según van ocurriendo. Por ejemplo si hay un cantante que ganó un concurso los últimos tres años seguidos, hay probabilidad alta de que vuelva a ganarlo este año.
El teorema bayesiano tiene tres bases que se pueden aplicar en una tabla de contingencia:
PROBABILIDAD CONJUNTA ➜ Se relaciona una intersección con el total.
PROBABILIDAD MARGINAL ➜ Se relacionan los marginales con el total.
PROBABILIDAD CONDICIONADA ➜ Se condiciona lo que sucede en un conjunto para que aparezca otra cosa. Es decir, dada una condición genera otra condición.
VARIABLES ALEATORIAS
Conceptos a tener en cuenta:
FRECUENCIA ABSOLUTA (fi) ➜ Cantidad de veces que aparece un dato en una muestra.
FRECUENCIA RELATIVA (fr) ➜ Posición/peso del dato en la muestra (Frecuencia absoluta dividido el tamaño de la muestra). El valor de las frecuencias relativas es igual o mayor a 0, y la suma de todas estas tiene que dar 1 (el espacio muestral es 1), si se cumplen esas dos condiciones se dice es que es una función de distribución de probabilidad.
*Cuando se calcula la probabilidad a posteriori la frecuencia relativa se puede tomar también como valor de probabilidad.
FRECUENCIA RELATIVA ACUMULADA (fra) ➜ Acumulación de los datos en cada intervalo. (Se van sumando las frecuencias relativas una por una).

VARIABLE ALEATORIA ➜ Asigna o asocia un valor numérico a cada resultado de un experimento aleatorio. Esos valores pueden ser discretos o continuos.
VARIABLE ALEATORIA DISCRETAS ➜ Números enteros o naturales (0, 1, 2, 3). Cuando se representan usando un grafico de barras, cada una de las barras van a estar mas separadas de lo normal.
VARIABLE ALEATORIA CONTINUA ➜ Números reales (0,41; 1,40; 1,03).
ESPERANZA MATEMÁTICA ➜ También llamado valor esperado. Es el valor mas probable en ausencia de información adicional, representando el promedio ponderado de la variable aleatoria. Se calcula multiplicando cada uno de los datos (xi) por su probabilidad (fr) y luego sumando los resultados.
Ejemplo (x = valor de dato; P = probabilidad o frecuencia relativa):

Sabemos que la suma de todas las probabilidades es igual a uno, por lo que para calcular el valor de 'y' hay que hacer 1 menos la suma de las probabilidades.
y = 1 - 0,7 = 0,3
Para calcular la esperanza matemática hay que multiplicar cada dato (x) por su probabilidad y luego sumar los resultados.
DISTRIBUCIONES DE PROBABILIDAD DISCRETA
La distribución de probabilidad discreta simplemente nos dice que probabilidad hay de que salga un resultado.
Ejemplo:
Si se tira un dado. ¿Que probabilidad hay de que salga un 1? Un dado tiene seis caras, y el numero 1 solamente aparece una vez, por lo que la probabilidad es de 1 de entre 6 (1/6).
¿Que probabilidad hay de que salga un 3? El dado tiene seis caras y solamente un 3, por lo que la probabilidad también es de 1/6.
Si en una bolsa hay diez frutas y de esas diez hay tres manzanas. ¿Que probabilidad hay de que salga una manzana si saco una fruta al azar? Tres de entre diez (3/10).
VARIABLES DICOTÓMICAS ➜ variables cualitativas que solo pueden tomar uno de dos valores posibles (si o no, hombre o mujer, verdadero o falso, etc).
➢ ENSAYO DE BERNOULLI
Experimento aleatorio en el que solo se pueden obtener dos resultados opuestos e independientes (ej: verdadero o falso).
El ensayo de Bernoulli tiene las siguientes características que se tienen que dar para que haya una distribución de probabilidad discreta:
- RESULTADOS MUTUAMENTE EXCLUYENTES ➜ Siempre hay dos posibles resultados, y si sale uno no puede ser el otro (si algo es verdadero, no puede ser también falso), por lo que se excluye el otro resultado.
- ENSAYOS INDEPENDIENTES ➜ El resultado de un ensayo no condiciona el resultado de los demás ensayos (si hay dos posibles resultados en los que tengo 50% de chance de que salga verdadero o falso. Si hago un ensayo y el resultado sale verdadero, este resultado no va a afectar la chance del próximo ensayo, el segundo también va a tener un 50% de chance de que sea verdadero o falso).
- PROBABILIDAD CONSTANTE ➜ La probabilidad de que ocurrencia de que salga verdadero o falso en diferentes ensayos siempre es la misma (50%).
ÉXITO ➜ Se da una respuesta favorable a lo que estamos analizando. Representada en cálculos como una 'P' (de Probabilidad de éxito) o un '1'.
*El "éxito" no necesariamente tiene que ser algo positivo. Por ejemplo si el enunciado es "¿Que probabilidad hay de que a una persona NO le guste el sushi?" el éxito van a ser las personas a las que no les guste.
FRACASO ➜ Se da una respuesta desfavorable. Representada como una 'Q', 1-P (o P complemento) o como un '0'.
*Siguiendo el mismo ejemplo anterior, el fracaso van a ser las personas a las que SI les guste el sushi.
Ejemplo:
Queremos saber las probabilidades de que a una persona le guste la pizza. Cuando le preguntamos si le gusta solamente hay dos respuestas: si o no. Y sabemos que la posibilidad de que a una persona le guste la pizza es de 0,8.
Éxito = 0,8
Fracaso = ?
Sabemos que la suma de las probabilidades de un experimento siempre va a ser igual a 1, por lo que para encontrar la probabilidad de fracaso se le resta la probabilidad de éxito.
Éxito = 0,8
Fracaso = 1 - 0,8 = 0,2
➢ DISTRIBUCIÓN BINOMIAL
Cuenta el numero de éxitos al repetir experimentos del tipo de ensayos de Bernoulli, y sus características son similares: resultados mutuamente excluyentes, ensayos independientes, probabilidad constante, y ademas el numero de ensayos debe ser fijo.
Ejercicio de ejemplo:
Si hay 10 pelotas en una caja, de las cuales 4 son blancas, y agarro una pelota al azar. ¿Si repito este ensayo 9 veces que probabilidad hay de que dos de esas pelotas salgan blancas?
Se que en un solo ensayo hay solo dos resultados posibles: que salga blanca o que no salga blanca. La probabilidad de que salga blanca es de 4/10 (o 0,4), mientras que la probabilidad de que no salga blanca es de 6/10 (o 0,6).
P = probabilidad de éxito = 4/10 = 0,4
Q = probabilidad de fracaso = 6/10 = 0,6
¿Que probabilidad hay que de esos 9 ensayos salga una pelota blanca dos veces?
*Para resolver este enunciado hay que recordar el binomio de Newton.
n = cantidad de ensayos = 9
P = 0,4
Q = 0,6
r = veces que debe salir una pelota blanca = 2
Para encontrar la respuesta se va a aplicar un método similar al que se usa para encontrar un termino en el binomio de Newton:
( n r ) P^r * Q^n-r =
( 9 2 ) 0,42 * 0,6^9-2 = 0,42 * 0,6^7 =
Para hacer desaparecer los números en paréntesis se utiliza una formula de factoriales y se multiplica por el resto de la ecuación:
n! / r! * ( n - r )! =
[ 9! / 2! * (9 - 2)! ] * 0,42 * 0,6^7 = ( 362880 / 10080) * 0,42 * 0,6^7
36 * 0,42 * 0,67 = 36 * 0,16 * 0,02799 = 0,1612
La probabilidad de que en 9 intentos salgan dos pelotas blancas es de 0,1612 o 16,12%.
➢ CALCULAR ESPERANZA Y VARIANZA
ESPERANZA ➜ Para este tipo de ejercicio para calcular la esperanza simplemente hay que multiplicar el numero de veces que se repite el ensayo por la probabilidad de éxito.
Si hay 10 pelotas en una caja de las cuales 4 son blancas y tomo una pelota. ¿Cual es la esperanza si repito el ensayo 50 veces?
n = cantidad de ensayos = 50
P = probabilidad de éxito = 0,4
Q = probabilidad de fracaso = 0,6
E = 50 * 0,4 = 20
La esperanza es de 20.
VARIANZA ➜ Para calcularla hay que multiplicar el numero de veces que se repite el ensayo, la probabilidad de éxito, y la probabilidad de fracaso.
Si hay 10 pelotas en una caja de las cuales 4 son blancas y tomo una pelota. ¿Cual es la varianza si repito el ensayo 50 veces?
Var = 50 * 0,4 * 0,6 = 12
La varianza es de 12.
➢ DISTRIBUCIÓN DE POISSON
Se puede utilizar este tipo de distribución para reemplazar a la binomial cuando el numero de ensayos (n) es muy grande y la probabilidad de éxito muy pequeña (p). La formula de probabilidad es la siguiente:

Ejemplo:
En un supermercado se recibe un promedio de 8 quejas diarias ¿Que probabilidad hay de que se reciban exactamente 10 quejas en un día?
r = cantidad de elementos en el continuo = 10
λ = promedio de presentación del elemento por cada unidad = 8
e = siempre tiene el valor de 2,71828183
( 2,71828183^-8 * 8^10 ) / 10! = ( 0.00033546262 * 1073741824 ) / 3628800
360200.245483 / 3628800 = 0.09926 = 0,0993
Hay una probabilidad de 0,0993 o 9,93% de recibir 10 quejas en un día.
-----